DNA and RNA

The entire genetic content of a cell is known as its genome, and the study of genomes is genomics. In eukaryotic cells but not in prokaryotes, DNA forms a complex with histone proteins to form chromatin, the substance of eukaryotic chromosomes. A chromosome may contain tens of thousands of genes. Many genes contain the information to make protein products; other genes code for RNA products. DNA controls all of the cellular activities by turning the genes “on” or “off.”
The other type of nucleic acid, RNA, is mostly involved in protein synthesis. The DNA molecules never leave the nucleus but instead use an intermediary to communicate with the rest of the cell. This intermediary is the messenger RNA (mRNA). Other types of RNA—like rRNA, tRNA, and microRNA—are involved in protein synthesis and its regulation.
DNA and RNA are made up of monomers known as nucleotides. The nucleotides combine with each other to form a polynucleotide, DNA or RNA. Each nucleotide is made up of three components: a nitrogenous base, a pentose (five-carbon) sugar, and a phosphate group (Figure ). Each nitrogenous base in a nucleotide is attached to a sugar molecule, which is attached to one or more phosphate groups.
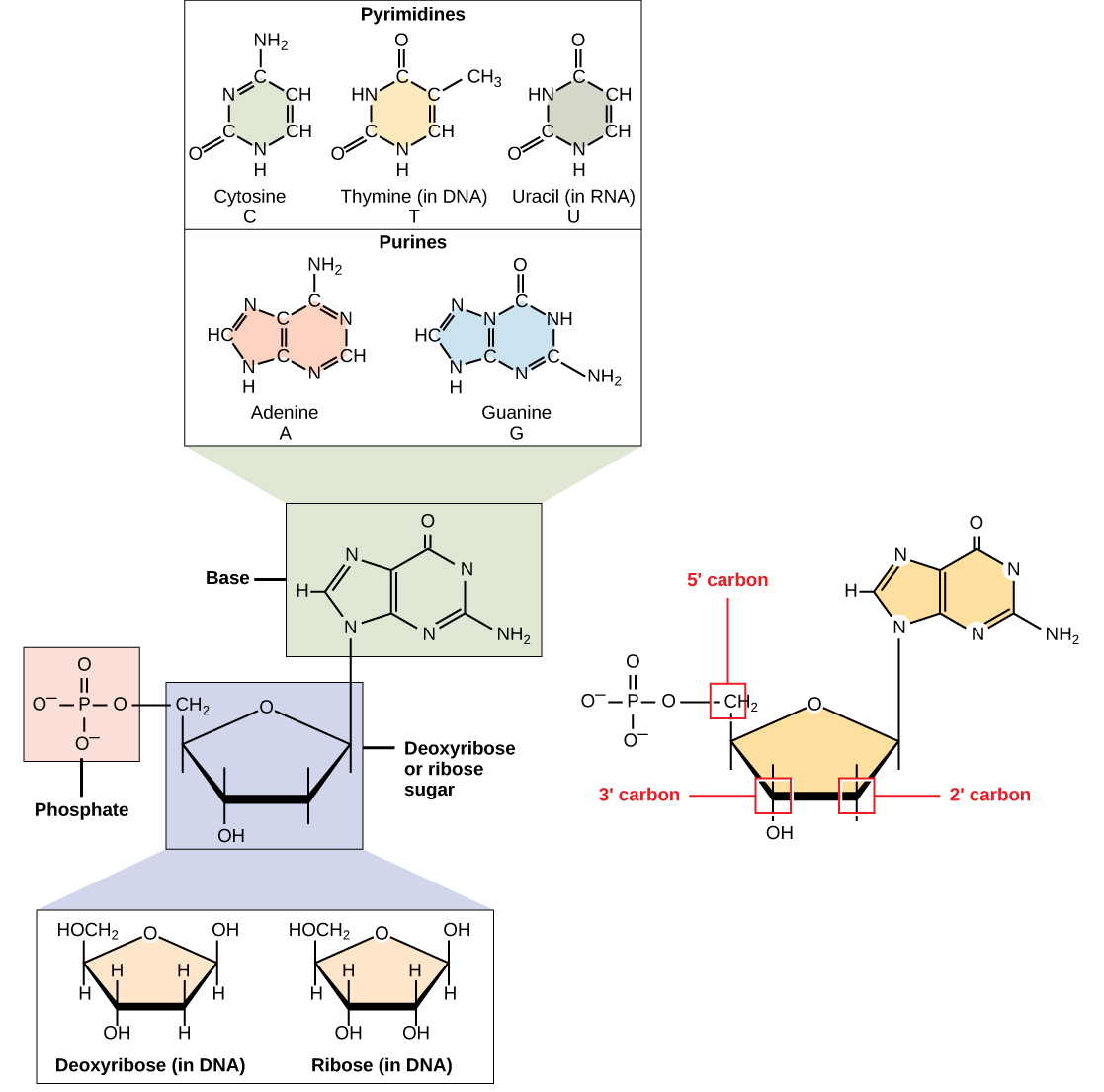
The nitrogenous bases, important components of nucleotides, are organic molecules and are so named because they contain carbon and nitrogen. They are bases because they contain an amino group that has the potential of binding an extra hydrogen, and thus, decreasing the hydrogen ion concentration in the environment, making it more basic. Each nucleotide in DNA contains one of four possible nitrogenous bases: adenine (A), guanine (G) cytosine (C), and thymine (T).
Adenine and guanine are classified as purines. The primary structure of a purine is two carbon-nitrogen rings. Cytosine, thymine, and uracil are classified as pyrimidines which have a single carbon-nitrogen ring as their primary structure (Figure ). Each of these basic carbon-nitrogen rings has different functional groups attached to it. In molecular biology shorthand, the nitrogenous bases are simply known by their symbols A, T, G, C, and U. DNA contains A, T, G, and C whereas RNA contains A, U, G, and C.
The pentose sugar in DNA is deoxyribose, and in RNA, the sugar is ribose (Figure ). The difference between the sugars is the presence of the hydroxyl group on the second carbon of the ribose and hydrogen on the second carbon of the deoxyribose (so deoxyribose is "missing" an -OH group). The carbon atoms of the sugar molecule are numbered as 1′, 2′, 3′, 4′, and 5′ (1′ is read as “one prime”).
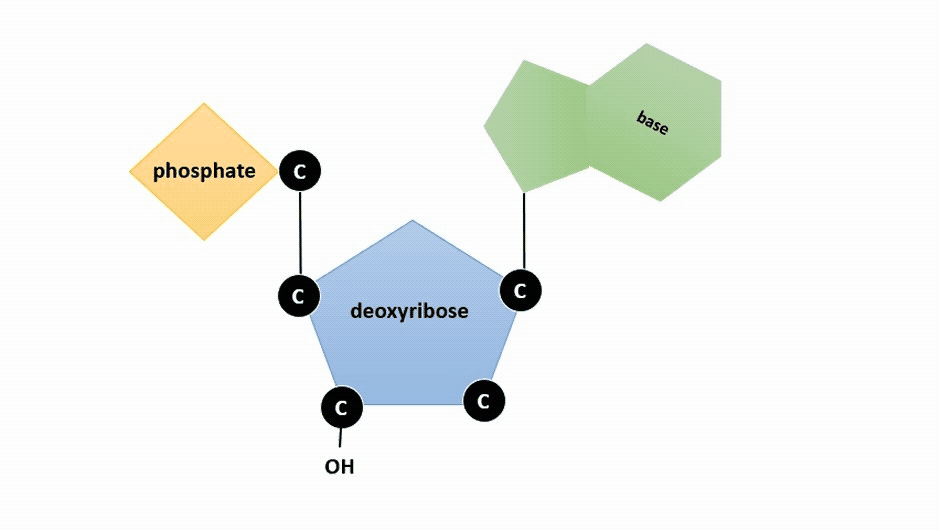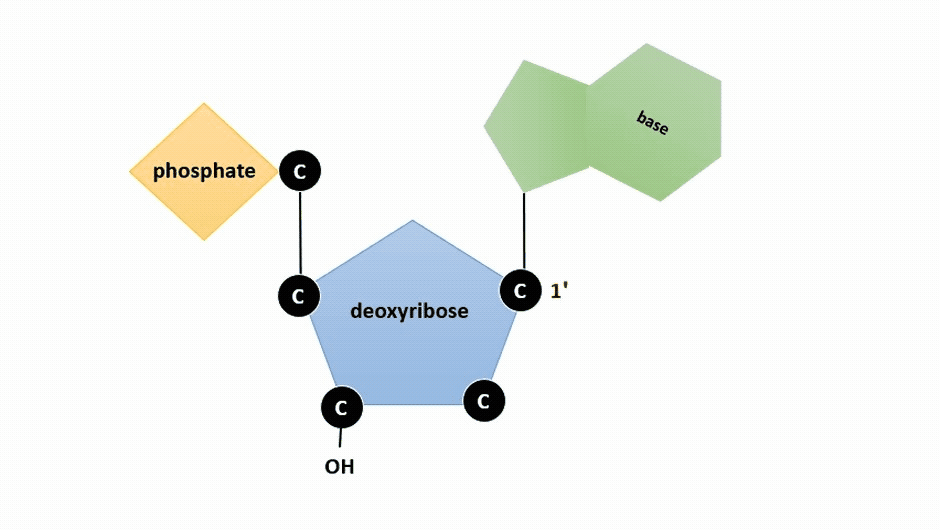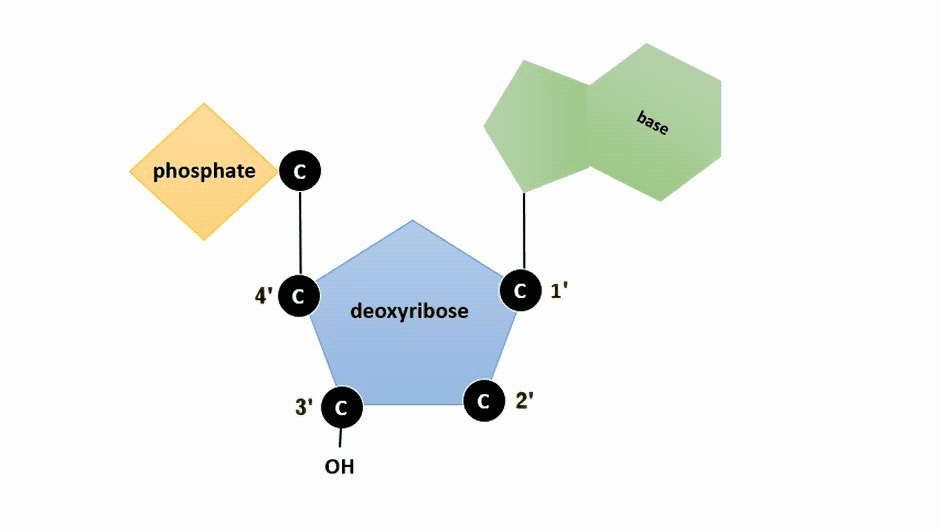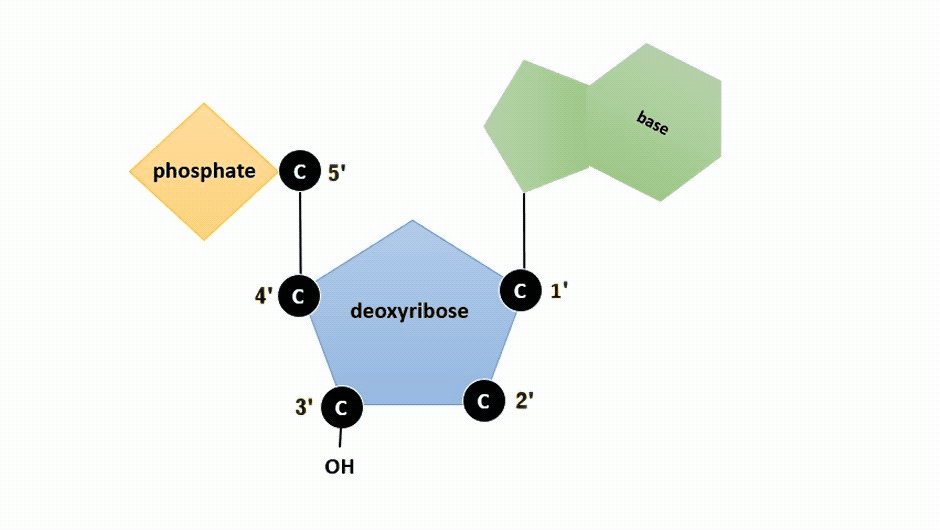
Figure : Animation highlighting carbons 1' through 5' on dexoyribose. (SWLeacock)
The phosphate residue is attached to the hydroxyl group of the 5′ carbon of one sugar and the hydroxyl group of the 3′ carbon of the sugar of the next nucleotide, which forms a 5′–3′ phosphodiester linkage. The phosphodiester linkage is not formed by simple dehydration reaction like the other linkages connecting monomers in macromolecules: its formation involves the removal of two phosphate groups. A polynucleotide may have thousands of such phosphodiester linkages.
Chargaff’s Rules
When Watson and Crick set out in the 1940’s to determine the structure of DNA, it was already known that DNA is made up of a series four different types of molecules, called bases or nucleotides: adenine (A), cytosine (C), thymine (T), guanine (G). Watson and Crick also knew of Chargaff’s Rules, which were a set of observations about the relative amount of each nucleotide that was present in almost any extract of DNA. Chargaff had observed that for any given species, the abundance of A was the same as T, and G was the same as C. This was essential to Watson & Crick’s model.
1.DNA Double-Helix Structure
Using proportional metal models of the individual nucleotides, Watson and Crick deduced a structure for DNA that was consistent with Chargaff’s Rules and with x-ray crystallography data that was obtained (with some controversy) from another researcher named Rosalind Franklin. In Watson and Crick’s famous double helix, each of the two strands contains DNA bases connected through covalent (phosphodiester) bonds to a sugar-phosphate backbone. Because one side of each sugar molecule is always connected to the opposite side of the next sugar molecule, each strand of DNA has polarity: these are called the 5’ (5-prime) end and the 3’ (3-prime) end, in accordance with the nomenclature of the carbons in the sugars. The two strands of the double helix run in anti-parallel (i.e. opposite) directions, with the 5’ end of one strand adjacent to the 3’ end of the other strand. The double helix has a right-handed twist, (rather than the left-handed twist that is often represented incorrectly in popular media). The DNA bases extend from the backbone towards the center of the helix, with a pair of bases from each strand forming hydrogen bonds that help to hold the two strands together. Under most conditions, the two strands are slightly offset, which creates a major groove on one face of the double helix, and a minor groove on the other.
- A pairs with T (or U if RNA)
- G pairs with C
Because of the structure of the bases, A can only form hydrogen bonds with T, and G can only form hydrogen bonds with C (remember Chargaff’s Rules). Each strand is therefore said to be complementary to the other, and so each strand also contains enough information to act as a template for the synthesis of the other. This complementary redundancy is important in DNA replication and repair. If the sequence of one strand is AATTGGCC, the complementary strand would have the sequence TTAACCGG. During DNA replication, each strand is copied, resulting in a daughter DNA double helix containing one parental DNA strand and a newly synthesized strand.
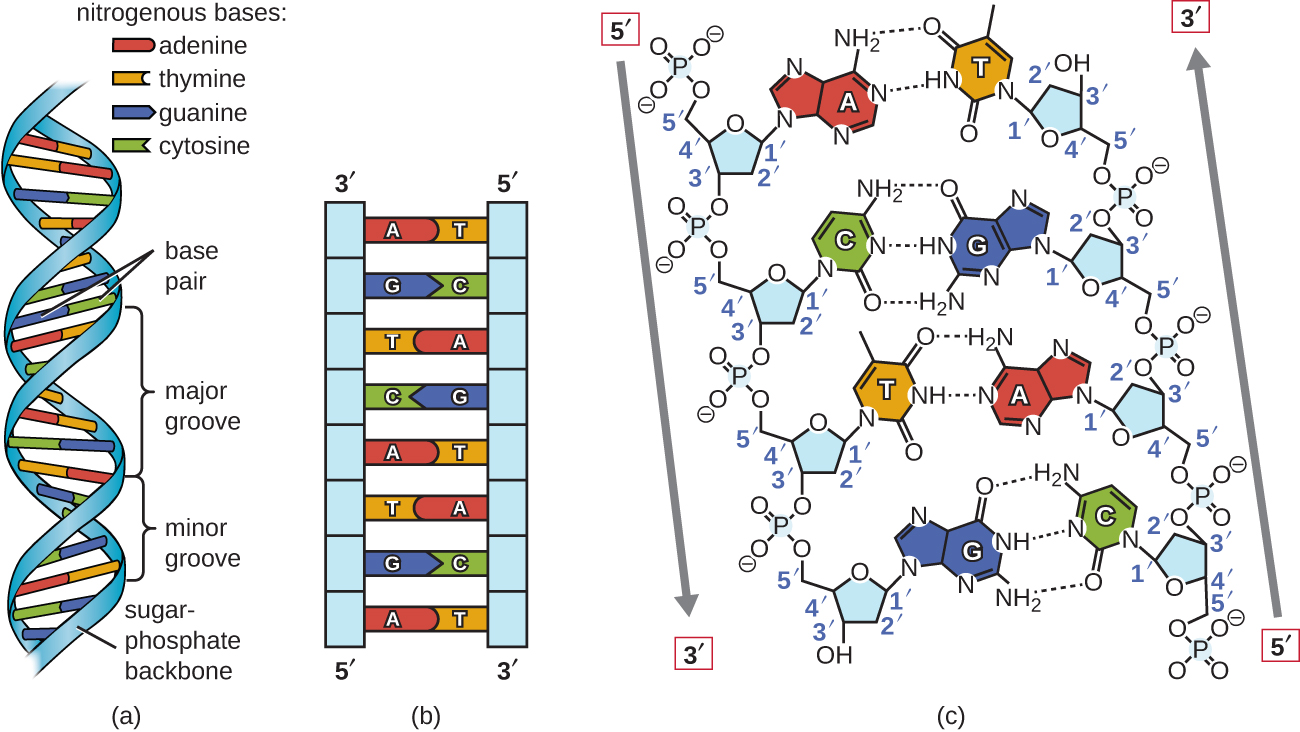
A complementary strand can always be synthesized from a single strand, due to the arrangement of hydrogen bonds between GC and AT bases.
- Hydrogen bonds stabilize the double helix, but can be broken when DNA needs to be accessed.
- The order of bases contains the information needed to code for amino acids in proteins during translation.
- Even sequences of DNA that do not encode amino acids can still provide information by interacting with proteins that function in DNA packaging and regulation. The major and minor grooves of DNA may determine which sequences are visible to DNA interacting proteins.
Post a Comment